





LLaMA Factory
Fine-tuning a large language model can be easy as the above demo video.
Choose your path:
- Colab: https://colab.research.google.com/drive/1eRTPn37ltBbYsISy9Aw2NuI2Aq5CQrD9?usp=sharing
- PAI-DSW: Llama3 Example | Qwen2-VL Example
- Local machine: Please refer to usage
- Documentation (WIP): https://llamafactory.readthedocs.io/zh-cn/latest/
[!NOTE]
Except for the above links, all other websites are unauthorized third-party websites. Please carefully use them.
Features
- Various models: LLaMA, LLaVA, Mistral, Mixtral-MoE, Qwen, Qwen2-VL, Yi, Gemma, Baichuan, ChatGLM, Phi, etc.
- Integrated methods: (Continuous) pre-training, (multimodal) supervised fine-tuning, reward modeling, PPO, DPO, KTO, ORPO, etc.
- Scalable resources: 16-bit full-tuning, freeze-tuning, LoRA and 2/3/4/5/6/8-bit QLoRA via AQLM/AWQ/GPTQ/LLM.int8/HQQ/EETQ.
- Advanced algorithms: GaLore, BAdam, Adam-mini, DoRA, LongLoRA, LLaMA Pro, Mixture-of-Depths, LoRA+, LoftQ, PiSSA and Agent tuning.
- Practical tricks: FlashAttention-2, Unsloth, Liger Kernel, RoPE scaling, NEFTune and rsLoRA.
- Experiment monitors: LlamaBoard, TensorBoard, Wandb, MLflow, etc.
- Faster inference: OpenAI-style API, Gradio UI and CLI with vLLM worker.
Benchmark
Compared to ChatGLM's P-Tuning, LLaMA Factory's LoRA tuning offers up to 3.7 times faster training speed with a better Rouge score on the advertising text generation task. By leveraging 4-bit quantization technique, LLaMA Factory's QLoRA further improves the efficiency regarding the GPU memory.
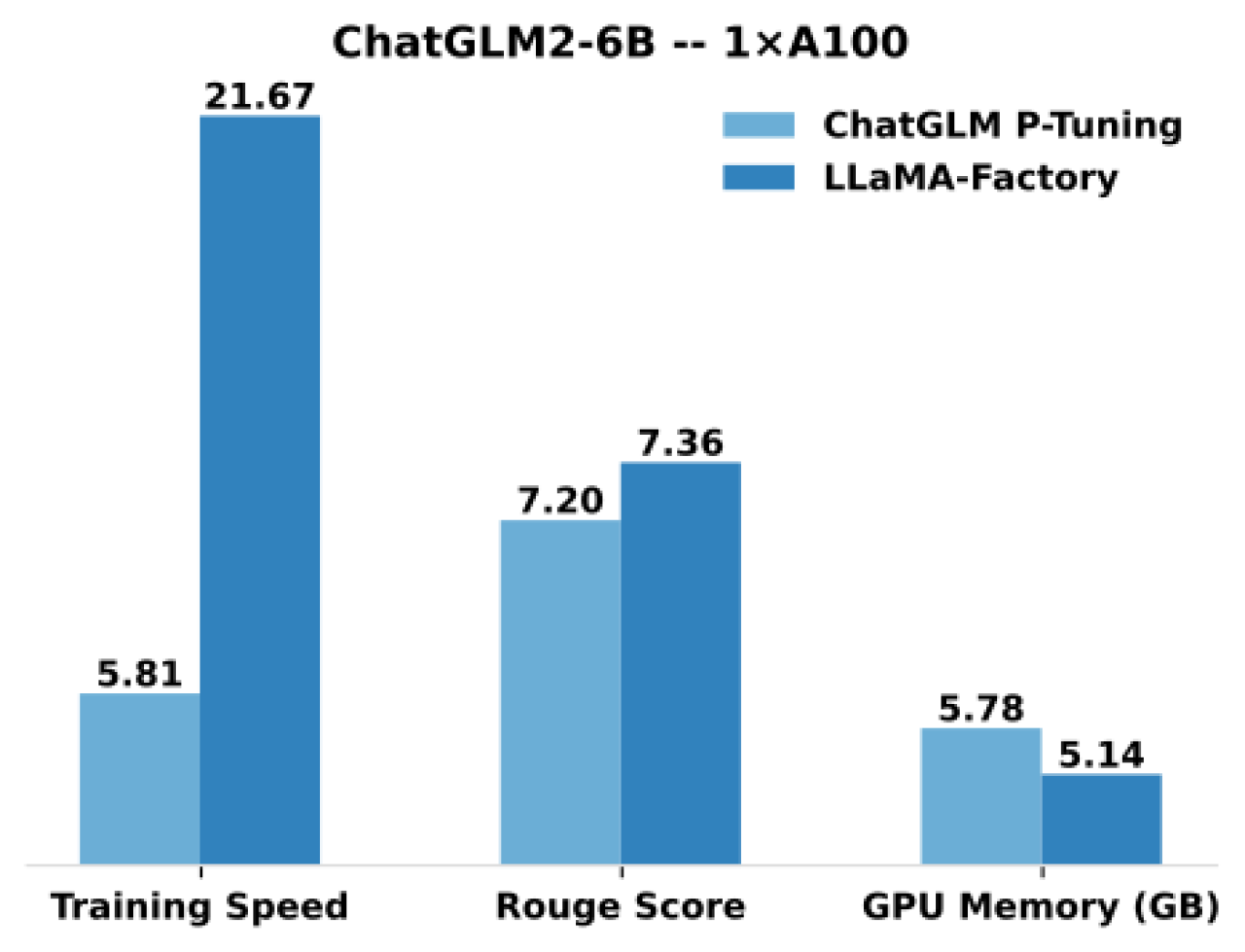
Definitions
- Training Speed: the number of training samples processed per second during the training. (bs=4, cutoff_len=1024)
- Rouge Score: Rouge-2 score on the development set of the advertising text generation task. (bs=4, cutoff_len=1024)
- GPU Memory: Peak GPU memory usage in 4-bit quantized training. (bs=1, cutoff_len=1024)
- We adopt
pre_seq_len=128for ChatGLM's P-Tuning andlora_rank=32for LLaMA Factory's LoRA tuning.
Supported Models
[!NOTE]
For the "base" models, thetemplateargument can be chosen fromdefault,alpaca,vicunaetc. But make sure to use the corresponding template for the "instruct/chat" models.Remember to use the SAME template in training and inference.
Please refer to constants.py for a full list of models we supported.
You also can add a custom chat template to template.py.
Supported Training Approaches
[!TIP]
The implementation details of PPO can be found in this blog.
Provided Datasets
Pre-training datasets
Supervised fine-tuning datasets
- Identity (en&zh)
- Stanford Alpaca (en)
- Stanford Alpaca (zh)
- Alpaca GPT4 (en&zh)
- Glaive Function Calling V2 (en&zh)
- LIMA (en)
- Guanaco Dataset (multilingual)
- BELLE 2M (zh)
- BELLE 1M (zh)
- BELLE 0.5M (zh)
- BELLE Dialogue 0.4M (zh)
- BELLE School Math 0.25M (zh)
- BELLE Multiturn Chat 0.8M (zh)
- UltraChat (en)
- OpenPlatypus (en)
- CodeAlpaca 20k (en)
- Alpaca CoT (multilingual)
- OpenOrca (en)
- SlimOrca (en)
- MathInstruct (en)
- Firefly 1.1M (zh)
- Wiki QA (en)
- Web QA (zh)
- WebNovel (zh)
- Nectar (en)
- deepctrl (en&zh)
- Advertise Generating (zh)
- ShareGPT Hyperfiltered (en)
- ShareGPT4 (en&zh)
- UltraChat 200k (en)
- AgentInstruct (en)
- LMSYS Chat 1M (en)
- Evol Instruct V2 (en)
- Cosmopedia (en)
- STEM (zh)
- Ruozhiba (zh)
- Neo-sft (zh)
- WebInstructSub (en)
- Magpie-Pro-300K-Filtered (en)
- Magpie-ultra-v0.1 (en)
- LLaVA mixed (en&zh)
- Pokemon-gpt4o-captions (en&zh)
- Open Assistant (de)
- Dolly 15k (de)
- Alpaca GPT4 (de)
- OpenSchnabeltier (de)
- Evol Instruct (de)
- Dolphin (de)
- Booksum (de)
- Airoboros (de)
- Ultrachat (de)
Preference datasets
Some datasets require confirmation before using them, so we recommend logging in with your Hugging Face account using these commands.
Requirement
Hardware Requirement
* estimated
Getting Started
Installation
[!IMPORTANT]
Installation is mandatory.
Extra dependencies available: torch, torch-npu, metrics, deepspeed, liger-kernel, bitsandbytes, hqq, eetq, gptq, awq, aqlm, vllm, galore, badam, adam-mini, qwen, modelscope, openmind, quality
[!TIP]
Usepip install --no-deps -e .to resolve package conflicts.
For Windows users
If you want to enable the quantized LoRA (QLoRA) on the Windows platform, you need to install a pre-built version of bitsandbytes library, which supports CUDA 11.1 to 12.2, please select the appropriate release version based on your CUDA version.
To enable FlashAttention-2 on the Windows platform, you need to install the precompiled flash-attn library, which supports CUDA 12.1 to 12.2. Please download the corresponding version from flash-attention based on your requirements.
For Ascend NPU users
To install LLaMA Factory on Ascend NPU devices, please specify extra dependencies: pip install -e ".[torch-npu,metrics]". Additionally, you need to install the Ascend CANN Toolkit and Kernels. Please follow the installation tutorial or use the following commands:
Remember to use ASCEND_RT_VISIBLE_DEVICES instead of CUDA_VISIBLE_DEVICES to specify the device to use.
If you cannot infer model on NPU devices, try setting do_sample: false in the configurations.
Data Preparation
Please refer to data/README.md for checking the details about the format of dataset files. You can either use datasets on HuggingFace / ModelScope / Modelers hub or load the dataset in local disk.
[!NOTE]
Please updatedata/dataset_info.jsonto use your custom dataset.
Quickstart
Use the following 3 commands to run LoRA fine-tuning, inference and merging of the Llama3-8B-Instruct model, respectively.
See examples/README.md for advanced usage (including distributed training).
[!TIP]
Usellamafactory-cli helpto show help information.
Fine-Tuning with LLaMA Board GUI (powered by Gradio)
Build Docker
For CUDA users:
For Ascend NPU users:
For AMD ROCm users:
Build without Docker Compose
For CUDA users:
For Ascend NPU users:
For AMD ROCm users:
Details about volume
hf_cache: Utilize Hugging Face cache on the host machine. Reassignable if a cache already exists in a different directory.ms_cache: Similar to Hugging Face cache but for ModelScope users.om_cache: Similar to Hugging Face cache but for Modelers users.data: Place datasets on this dir of the host machine so that they can be selected on LLaMA Board GUI.output: Set export dir to this location so that the merged result can be accessed directly on the host machine.
Deploy with OpenAI-style API and vLLM
[!TIP]
Visit this page for API document.
Download from ModelScope Hub
If you have trouble with downloading models and datasets from Hugging Face, you can use ModelScope.
Train the model by specifying a model ID of the ModelScope Hub as the model_name_or_path. You can find a full list of model IDs at ModelScope Hub, e.g., LLM-Research/Meta-Llama-3-8B-Instruct.
Download from Modelers Hub
You can also use Modelers Hub to download models and datasets.
Train the model by specifying a model ID of the Modelers Hub as the model_name_or_path. You can find a full list of model IDs at Modelers Hub, e.g., TeleAI/TeleChat-7B-pt.
Use W&B Logger
To use Weights & Biases for logging experimental results, you need to add the following arguments to yaml files.
Set WANDB_API_KEY to your key when launching training tasks to log in with your W&B account.
Projects using LLaMA Factory
If you have a project that should be incorporated, please contact via email or create a pull request.
Click to show
- Wang et al. ESRL: Efficient Sampling-based Reinforcement Learning for Sequence Generation. 2023. [arxiv]
- Yu et al. Open, Closed, or Small Language Models for Text Classification? 2023. [arxiv]
- Wang et al. UbiPhysio: Support Daily Functioning, Fitness, and Rehabilitation with Action Understanding and Feedback in Natural Language. 2023. [arxiv]
- Luceri et al. Leveraging Large Language Models to Detect Influence Campaigns in Social Media. 2023. [arxiv]
- Zhang et al. Alleviating Hallucinations of Large Language Models through Induced Hallucinations. 2023. [arxiv]
- Wang et al. Know Your Needs Better: Towards Structured Understanding of Marketer Demands with Analogical Reasoning Augmented LLMs. KDD 2024. [arxiv]
- Wang et al. CANDLE: Iterative Conceptualization and Instantiation Distillation from Large Language Models for Commonsense Reasoning. ACL 2024. [arxiv]
- Choi et al. FACT-GPT: Fact-Checking Augmentation via Claim Matching with LLMs. 2024. [arxiv]
- Zhang et al. AutoMathText: Autonomous Data Selection with Language Models for Mathematical Texts. 2024. [arxiv]
- Lyu et al. KnowTuning: Knowledge-aware Fine-tuning for Large Language Models. 2024. [arxiv]
- Yang et al. LaCo: Large Language Model Pruning via Layer Collaps. 2024. [arxiv]
- Bhardwaj et al. Language Models are Homer Simpson! Safety Re-Alignment of Fine-tuned Language Models through Task Arithmetic. 2024. [arxiv]
- Yang et al. Enhancing Empathetic Response Generation by Augmenting LLMs with Small-scale Empathetic Models. 2024. [arxiv]
- Yi et al. Generation Meets Verification: Accelerating Large Language Model Inference with Smart Parallel Auto-Correct Decoding. ACL 2024 Findings. [arxiv]
- Cao et al. Head-wise Shareable Attention for Large Language Models. 2024. [arxiv]
- Zhang et al. Enhancing Multilingual Capabilities of Large Language Models through Self-Distillation from Resource-Rich Languages. 2024. [arxiv]
- Kim et al. Efficient and Effective Vocabulary Expansion Towards Multilingual Large Language Models. 2024. [arxiv]
- Yu et al. KIEval: A Knowledge-grounded Interactive Evaluation Framework for Large Language Models. ACL 2024. [arxiv]
- Huang et al. Key-Point-Driven Data Synthesis with its Enhancement on Mathematical Reasoning. 2024. [arxiv]
- Duan et al. Negating Negatives: Alignment without Human Positive Samples via Distributional Dispreference Optimization. 2024. [arxiv]
- Xie and Schwertfeger. Empowering Robotics with Large Language Models: osmAG Map Comprehension with LLMs. 2024. [arxiv]
- Wu et al. Large Language Models are Parallel Multilingual Learners. 2024. [arxiv]
- Zhang et al. EDT: Improving Large Language Models' Generation by Entropy-based Dynamic Temperature Sampling. 2024. [arxiv]
- Weller et al. FollowIR: Evaluating and Teaching Information Retrieval Models to Follow Instructions. 2024. [arxiv]
- Hongbin Na. CBT-LLM: A Chinese Large Language Model for Cognitive Behavioral Therapy-based Mental Health Question Answering. COLING 2024. [arxiv]
- Zan et al. CodeS: Natural Language to Code Repository via Multi-Layer Sketch. 2024. [arxiv]
- Liu et al. Extensive Self-Contrast Enables Feedback-Free Language Model Alignment. 2024. [arxiv]
- Luo et al. BAdam: A Memory Efficient Full Parameter Training Method for Large Language Models. 2024. [arxiv]
- Du et al. Chinese Tiny LLM: Pretraining a Chinese-Centric Large Language Model. 2024. [arxiv]
- Ma et al. Parameter Efficient Quasi-Orthogonal Fine-Tuning via Givens Rotation. ICML 2024. [arxiv]
- Liu et al. Dynamic Generation of Personalities with Large Language Models. 2024. [arxiv]
- Shang et al. How Far Have We Gone in Stripped Binary Code Understanding Using Large Language Models. 2024. [arxiv]
- Huang et al. LLMTune: Accelerate Database Knob Tuning with Large Language Models. 2024. [arxiv]
- Deng et al. Text-Tuple-Table: Towards Information Integration in Text-to-Table Generation via Global Tuple Extraction. 2024. [arxiv]
- Acikgoz et al. Hippocrates: An Open-Source Framework for Advancing Large Language Models in Healthcare. 2024. [arxiv]
- Zhang et al. Small Language Models Need Strong Verifiers to Self-Correct Reasoning. ACL 2024 Findings. [arxiv]
- Zhou et al. FREB-TQA: A Fine-Grained Robustness Evaluation Benchmark for Table Question Answering. NAACL 2024. [arxiv]
- Xu et al. Large Language Models for Cyber Security: A Systematic Literature Review. 2024. [arxiv]
- Dammu et al. "They are uncultured": Unveiling Covert Harms and Social Threats in LLM Generated Conversations. 2024. [arxiv]
- Yi et al. A safety realignment framework via subspace-oriented model fusion for large language models. 2024. [arxiv]
- Lou et al. SPO: Multi-Dimensional Preference Sequential Alignment With Implicit Reward Modeling. 2024. [arxiv]
- Zhang et al. Getting More from Less: Large Language Models are Good Spontaneous Multilingual Learners. 2024. [arxiv]
- Zhang et al. TS-Align: A Teacher-Student Collaborative Framework for Scalable Iterative Finetuning of Large Language Models. 2024. [arxiv]
- Zihong Chen. Sentence Segmentation and Sentence Punctuation Based on XunziALLM. 2024. [paper]
- Gao et al. The Best of Both Worlds: Toward an Honest and Helpful Large Language Model. 2024. [arxiv]
- Wang and Song. MARS: Benchmarking the Metaphysical Reasoning Abilities of Language Models with a Multi-task Evaluation Dataset. 2024. [arxiv]
- Hu et al. Computational Limits of Low-Rank Adaptation (LoRA) for Transformer-Based Models. 2024. [arxiv]
- Ge et al. Time Sensitive Knowledge Editing through Efficient Finetuning. ACL 2024. [arxiv]
- Tan et al. Peer Review as A Multi-Turn and Long-Context Dialogue with Role-Based Interactions. 2024. [arxiv]
- Song et al. Turbo Sparse: Achieving LLM SOTA Performance with Minimal Activated Parameters. 2024. [arxiv]
- Gu et al. RWKV-CLIP: A Robust Vision-Language Representation Learner. 2024. [arxiv]
- Chen et al. Advancing Tool-Augmented Large Language Models: Integrating Insights from Errors in Inference Trees. 2024. [arxiv]
- Zhu et al. Are Large Language Models Good Statisticians?. 2024. [arxiv]
- Li et al. Know the Unknown: An Uncertainty-Sensitive Method for LLM Instruction Tuning. 2024. [arxiv]
- Ding et al. IntentionQA: A Benchmark for Evaluating Purchase Intention Comprehension Abilities of Language Models in E-commerce. 2024. [arxiv]
- He et al. COMMUNITY-CROSS-INSTRUCT: Unsupervised Instruction Generation for Aligning Large Language Models to Online Communities. 2024. [arxiv]
- Lin et al. FVEL: Interactive Formal Verification Environment with Large Language Models via Theorem Proving. 2024. [arxiv]
- Treutlein et al. Connecting the Dots: LLMs can Infer and Verbalize Latent Structure from Disparate Training Data. 2024. [arxiv]
- Feng et al. SS-Bench: A Benchmark for Social Story Generation and Evaluation. 2024. [arxiv]
- Feng et al. Self-Constructed Context Decompilation with Fined-grained Alignment Enhancement. 2024. [arxiv]
- Liu et al. Large Language Models for Cuffless Blood Pressure Measurement From Wearable Biosignals. 2024. [arxiv]
- Iyer et al. Exploring Very Low-Resource Translation with LLMs: The University of Edinburgh's Submission to AmericasNLP 2024 Translation Task. AmericasNLP 2024. [paper]
- Li et al. Calibrating LLMs with Preference Optimization on Thought Trees for Generating Rationale in Science Question Scoring. 2024. [arxiv]
- Yang et al. Financial Knowledge Large Language Model. 2024. [arxiv]
- Lin et al. DogeRM: Equipping Reward Models with Domain Knowledge through Model Merging. 2024. [arxiv]
- Bako et al. Evaluating the Semantic Profiling Abilities of LLMs for Natural Language Utterances in Data Visualization. 2024. [arxiv]
- Huang et al. RoLoRA: Fine-tuning Rotated Outlier-free LLMs for Effective Weight-Activation Quantization. 2024. [arxiv]
- Jiang et al. LLM-Collaboration on Automatic Science Journalism for the General Audience. 2024. [arxiv]
- Inouye et al. Applied Auto-tuning on LoRA Hyperparameters. 2024. [paper]
- Qi et al. Research on Tibetan Tourism Viewpoints information generation system based on LLM. 2024. [arxiv]
- Xu et al. Course-Correction: Safety Alignment Using Synthetic Preferences. 2024. [arxiv]
- Sun et al. LAMBDA: A Large Model Based Data Agent. 2024. [arxiv]
- Zhu et al. CollectiveSFT: Scaling Large Language Models for Chinese Medical Benchmark with Collective Instructions in Healthcare. 2024. [arxiv]
- Yu et al. Correcting Negative Bias in Large Language Models through Negative Attention Score Alignment. 2024. [arxiv]
- Xie et al. The Power of Personalized Datasets: Advancing Chinese Composition Writing for Elementary School through Targeted Model Fine-Tuning. IALP 2024. [paper]
- Liu et al. Instruct-Code-Llama: Improving Capabilities of Language Model in Competition Level Code Generation by Online Judge Feedback. ICIC 2024. [paper]
- Wang et al. Cybernetic Sentinels: Unveiling the Impact of Safety Data Selection on Model Security in Supervised Fine-Tuning. ICIC 2024. [paper]
- Xia et al. Understanding the Performance and Estimating the Cost of LLM Fine-Tuning. 2024. [arxiv]
- Zeng et al. Perceive, Reflect, and Plan: Designing LLM Agent for Goal-Directed City Navigation without Instructions. 2024. [arxiv]
- Xia et al. Using Pre-trained Language Model for Accurate ESG Prediction. FinNLP 2024. [paper]
- Liang et al. I-SHEEP: Self-Alignment of LLM from Scratch through an Iterative Self-Enhancement Paradigm. 2024. [arxiv]
- StarWhisper: A large language model for Astronomy, based on ChatGLM2-6B and Qwen-14B.
- DISC-LawLLM: A large language model specialized in Chinese legal domain, based on Baichuan-13B, is capable of retrieving and reasoning on legal knowledge.
- Sunsimiao: A large language model specialized in Chinese medical domain, based on Baichuan-7B and ChatGLM-6B.
- CareGPT: A series of large language models for Chinese medical domain, based on LLaMA2-7B and Baichuan-13B.
- MachineMindset: A series of MBTI Personality large language models, capable of giving any LLM 16 different personality types based on different datasets and training methods.
- Luminia-13B-v3: A large language model specialized in generate metadata for stable diffusion. [????Demo]
- Chinese-LLaVA-Med: A multimodal large language model specialized in Chinese medical domain, based on LLaVA-1.5-7B.
- AutoRE: A document-level relation extraction system based on large language models.
- NVIDIA RTX AI Toolkit: SDKs for fine-tuning LLMs on Windows PC for NVIDIA RTX.
- LazyLLM: An easy and lazy way for building multi-agent LLMs applications and supports model fine-tuning via LLaMA Factory.
License
This repository is licensed under the Apache-2.0 License.
Please follow the model licenses to use the corresponding model weights: Baichuan 2 / BLOOM / ChatGLM3 / Command R / DeepSeek / Falcon / Gemma / GLM-4 / InternLM2 / Llama / Llama 2 (LLaVA-1.5) / Llama 3 / MiniCPM / Mistral / OLMo / Phi-1.5/Phi-2 / Phi-3 / Qwen / StarCoder 2 / XVERSE / Yi / Yi-1.5 / Yuan 2
Citation
If this work is helpful, please kindly cite as:
Acknowledgement
This repo benefits from PEFT, TRL, QLoRA and FastChat. Thanks for their wonderful works.
Star History
No reviews found!















No comments found for this product. Be the first to comment!